Probability plays a central role in this blog—many of my posts focus on where probability makes contact with philosophy and physics. However, there is also of course the mathematical theory of probability. The mathematics and the;philosophy interact in many ways, often technical results in the mathematics can be important for our work as philosophers.
For today’s post I want to dive into a paper that focuses on the more mathematical side of probability. The paper itself is very technical, and so I wont be focusing on explaining how the proof or argument in the paper works. Instead I am to provide the reader with an introduction to a few of the key concepts used in the paper, so that I can state the result of the paper with something approaching clarity.
***The original paper can be found here.***
There are three main concepts I want to discuss. The first is cardinality, the second is additivity, and the third is reflection/conglomerability. If you skim the post it will look mathematical and it is, but I give you all the tools you need to follow along—no previous knowledge required.
I
The fundamental objects in mathematics are sets. A set is a collection of elements. For example, the set 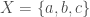
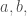



Things become trickier when we move to infinite sets. For example, the set of natural numbers 
Does this mean that there are all the finite numbers, and then infinity, and these are all the possible cardinal numbers? Not quite. There are actually infinities of different sizes. To keep this separate, we would want to assign different cardinal numbers to different sizes.
To see that there are different sizes of infinities, we need to think a little more carefully about the size of a set. The natural numbers are easy because they fit our intuition. If one set has 3 members and one set has 5, then the latter clearly is larger than the former. What about the set of natural numbers from before, 

On one line of thought, it looks like 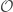
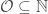
This is not the notion mathematicians use, and we can see why. First off, it doesn’t capture simple cases. For example, the set 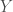

Neither is a subset of the other, and it is unclear how we should make the judgement. Are these two sets simply incomparable in size? That would certainly be an impoverished notion of cardinality.
Mathematicians have an answer to this problem, and it involves a special type of function called a bijection. You can think of a function that takes an object from one set which we call the domain, say, 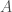
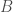
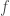





Now we can define a rigorous notion of cardinality. The cardinality of two sets 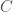
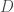
Consider two sets 

Notice that this satisfies our definition of a bijection. Each element of 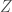

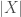
Notice that this allows us to compare the finite sets as well. Consider the sets 

Thus, 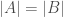

However, we can also use this to show that the set of all odd numbers has the same cardinality as the set of naturals. We can see this because for the two sets

we can define the function

and this also satisfies the properties of a bijection.
Now we can finally answer one of our earlier questions: are there different sizes of infinities? To show why this has to be the case I want to introduce the notion of a powerset. The powerset 

We can see in this case that 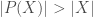
Cantor, one of the founders of set theory, proved that for any set 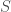
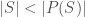
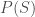



With this set up, consider the question: is the set 


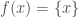
This is a fundamental result in set theory. It shows that there is a whole hierarchy of infinities—a whole hierarchy of cardinalities. Thus, we have a whole host of different infinite cardinalities to choose from. The 
II
The next concept is additivity. In particular, we are talking about the additivity of a probability function. Additivity tells us something about how we sum probabilities of different events.
In probability theory we work with something called an event space—this is a set of events. For example, if we are rolling a die, the event space might be the set 
An event is a subset of this space. For example, rolling a 5 is an event—this is the set $\{5\}$. However, rolling an even number is also an event. This would correspond to a the set 
Knowing the probability of each of the basic events—the sides of the die—which in this case is one sixth, we might want to ask if we can calculate the probability of a different event, like rolling an even number.
Our intuition says that we sum up the probabilities of the individual basic events. For the even event, this means summing 
What we are appealing to here is a hidden additivity principle. We have a probability function that takes as input an event, like rolling a 3—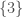

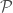
For example, consider the principle that if an event is the union—the set that contains all the elements of both sets, for example, 

That was a little abstract, so let us consider an example. Suppose we are interested in the probability tat we get either a 1 or a 6. This is the event 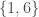
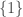


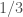
However, we see that from 2-additivity we get finite-additivity for free. A probability function is finitely additive if the probability of any event that is the disjoint union of finite n events is the sum of the probability of those n events.
In order to see how we get this for free from 2 additivity, consider the earlier case of the even event, 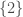




Our example of the die roll was one of a finite event space. There were only 6 possible outcomes. However, in science we regularly consider infinite event spaces. Thus, we might want to consider probability functions that have greater types of additivity. One type is countable additivity, which allows you to sum up the probabilities of events with cardinality 
Most commonly used in probability theory is countable additivity, but we can still in principle think about higher degrees of additivity , of size for example cardinality 
III
The last concept I want to introduce before stating the result of the paper is that of reflection/conglomerability. They are actually two different concepts, but I think starting with reflection provides a nice way to understand why conglomerability is interesting from a philosophical perspective.
The principle of reflection is a constraint on a rational agen’ts probabilities. Consider an agent who is about the undergo a learning experience, in which she will observe one element of a partition. A partition is a set of events that are disjoint from each other, and that cover the whole space. For example, we our die case from before, one partition might be the two sets 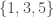
Reflection puts constraints on an agent’s current beliefs based on her possible future beliefs. For example, suppose that we want to know what an agent’s degree of belief that the die came up 1 should be. (Intuitively we think 1/6, but let us follow through this example to illustrate reflection, which can help us in more challenging cases). Suppose that her degree of belief in the die coming up 1 conditional on the even event is 0—that is, if she observes the even event then her new degree of belief in 1 will be 0 (since 1 is not even)—and her degree of belief in the die coming up 1 conditional on the odd event is 1/3. Furthermore, suppose that she assigns a credence of 0.5 to the roll being odd and a credence of 0.5 to the roll being even.
Reflection says that an agent’s current degree of belief in a proposition should be equal to the agent’s expectation of her future degree of belief. I illustrate this with the above case. If the agent learns that the roll was odd, then he probability in the proposition “the roll came up 1” is 1/3. If the agent learns that the roll was even, then he probability in the proposition “the roll came up 1” is 0. She assigns each of these cases probability 0.5. Thus, before she learns whether it was odd or even, her expectation of her future degree of belief is 
This connection to rationality can help us to see why conglomerability is interesting. Consider a probability function, an event space, and an event. The conditional probabilities are conglomerable with respect to a partition of size 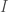




The authors give a nice summary of how this is interesting from an epistemic perspective:
Conglomerability is an intuitively plausible property that probabilities might be required to have. Suppose that one thinks of the conditional probability
(p. 285)as representing one’s degree of belief in
is true. Then
for all i in
Thus we see how we can capture an epistemic condition in a formal definition. Ideally we want our probability functions to be conglomerable.
IV
We can now state the main result of the paper, more or less. The main result is that
Subject to several structural assumptions…the cardinality
(p. 289)of a partition where [the probability function]
is nonconglomerable is bounded above by the (least) cardinal for which
In other words, there will be a partition, of size at most
So what is the story here? We have an epistemic principle, something like a conservation of evidence principle, that we want our probability functions to satisfy. However, we have a mathematical result that says that this is impossible for certain large cardinalities in certain contexts. Thus, we have a case in which we clearly see highly technical work filter back up into our epistemology. Even though in some sense it is desirable that our beliefs should satisfy this property, it may in fact be impossible. We should not require rational agents to do the impossible.
Mathematical results can limit and inform our philosophy. We need to pay attention to them.
