One joke about philosophers is that we walk around all day just going, “what does it all mean?” Though it is a joke, some philosophers are concerned with meaning. I don’t mean meaning in a kind of ethical, “why are we here?” sense (although some philosophers are concerned with that), but rather what we mean when when we talk about language, or actions, or events having meaning.
The study of meaning is called semantics, which can also mean the meaning of something. So if we are talking about the semantics of a sentence, we are talking about its meaning.
Another concept in this general area is information. We often think that some messages are more informative than others, and that one main goal of communication (if not the goal) is to share information. We might wonder, then, what is the connection between information and meaning?
This is the main question that Alistair Isaac explores in his paper “The Semantics Latent in Shannon Information”. In particular, he argues that information theory–the mathematical theory of information–can provide us with an account of meaning.
***The original paper can be found here.***
Isaac provides a very nice introduction to information theory, which I will loosely follow here, avoiding some of the mathematical details (which are in the paper).
We start off with a set of events–for example, an event might be a particular leaf falling off a tree, or that a cure for cancer is discovered, or that I utter the sentence “we’ve discovered a cure for cancer!” Each of these is an event. What we are interested in is the amount of information that one event conveys about another.
In an earlier post, we’ve looked at how the degrees of belief of rational agents can be characterized as probabilities. When we observe some evidence, we update our belief in our hypothesis using Bayes’ theorem. This can give us an insight into how we want to think about information — it will be connected to probability.
What do we want out a theory of information? We can think of a few conditions. First, if an event is certain to happen, then when it does we want it to convey no information. This is because we haven’t learned anything new. Thus, for an event 

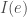
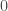
We also want every possible event to contain positive (or at least non-negative) information. We can think of this as worse-case the event tells us nothing about the world, in which case it contain 0 information, or it tells us something–we don’t need an account of “negative information” — we’re not sure what that would mean.
We also want the information of an event to be a decreasing function of its probability. We can think of this in terms of how surprised we are. If we really expect something to happen, and so assign it very high probability, and it does happen, we haven’t gained much information. However, if we think something is really unlikely, and then we observe it, we have gained a lot of information. The slogan is that the more surprised we are by an event, the more information that event contains. As we become more and more surprised, we want the information that the event contains to approach 
Finally, if two events are probabilistic independent, that is, 

Now, if you are a little familiar with logarithms, you can see why the logarithm might come to mind, particularly because it has the property that 
That is, we can think of information of an event as the negative logarithm of the probability of an event. Through a quick visual inspection of the graph of 
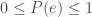
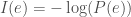

In fact, not only does it satisfy these conditions, but any function that does so will be proportional to
Now we have a handle on the information of a single event. We can also think about the information that we expect something like an experiment or a conversation to have. Consider, for an analogy, that you are rolling a 6-sided die, and that you get $1 for each pip. So, if the die comes up 1, then you get $1, if it comes up 2, you get $2, et cetera. We can think of the expected monetary value of a single die roll by multiplying the probability of each outcome by its value. So, for a die, we have that the expected value of the roll

So, the expected value of the die role is $3.5. There is nothing special about money, though; we can calculate do it with any quantity, including information. So, if there are some number 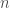

H is called the Shannon entropy , and measures how informative we expect something to be on average.
Now we are in a position to figure out how much one event contains about another. As Isaac writes, “The basic idea is that subtracting the information in 
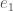
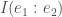

Now we can return to our original question — can information tell us anything about meaning? So far it looks like we have an account of information quantity, but not information content. Indeed, this is the standard stance in the field. However, Isaac argues that we can use notions from information theory to also give an account of information content.
How do we do this? The idea is as follows. We want to know the meaning of an event — say, a sentence, or message — 

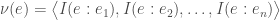
Isaac calls this an s-vector. It is really just a list that has, for each event, the information that 
Isaac also argues in detail why such a semantics gives us pretty much all of what we would want out of an account of meaning. I’ve given you a few reasons, but if you want a more detailed philosophical analysis it is there in the original paper. In this post I’ve tried to get most of the moving parts there on the table. I really like this approach to thinking about meaning, as it interfaces nicely with both subjective Bayesianism and information theory.
