Probability can seem like a slippery notion. Indeed, though we have an intuitive notion of various aspects of probability, it took a long time for humanity to develop a rigorous formal theory. And even with the mathematics of probability on surer footing, the interpretation of probability — what does it mean — is still plagued with puzzles and often contested. (Though, at least in my field, Bayesians certainly seem to have the upper hand.)
Thus, even though we have a much better understand of probability now than ever before, there is still work to be done. Furthermore, we don’t often appreciate how hard-won some of our insights are. For these reasons I think it is instructive and helpful to look at how people thought of probability in the past — both to give us examples of pitfalls into which we ourselves might fall, and to get a better understanding of the vastness and topography of our field of inquiry. Thus to this end I want to take a close look at a 1937 paper by R. W. Ditchburn.
***The original paper can be found here.***
This is a very short paper — more of a note — and so this post will be more in the format of an annotated paper than my classic style. Thus, the quotes are all in exact order. A note: for quotations, if there is a minor typographical error in the paper I sometimes correct it.
The paper begins:
Mathematical discussions on probability often seem to me to have a false and, indeed, an impossible objective. The older theory of ‘exact’ physics consisted of an axiomatic theory, which provided a series of equations requiring the insertion of one or more arbitrary constants to complete them.
Here Ditchburn is setting up his critique of the one of the (then) modern goals of probability. He begins to draw a parallel between the role probability is supposed to play in the sciences with the role constants play in physics. An example of the kind of constants he is talking about in ‘exact’ physics would be something like 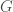
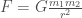
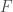



These constants were supposed to be given exactly by the results of past experiments. When these constants were inserted into the equations the axiomatic theory gave exact and certain predictions concerning the results of future experiments. If the predictions did not agree with the experiments either there was an experimental error or the axiomatic theory required modification.
So the way we find constants like
The aim of theories of probability has been to deal with indefinitely long sequences in exactly the same way as the older theory dealt with ordinary dynamical variables like position and velocity. It is supposed that from indefinitely long runs frequencies can be deduced and that these can be inserted into the axiomatic theory (because they are effectively constants) and that the axiomatic theory can then give exact and certain predictions of indefinitely long runs in the future. If the theory and experiment do not agree it is either because the sequences are not long enough (this is analogous to be experimental error) or because the axiomatic theory has not been correctly worked out.
This is the parallel between probability and constants. According to this view, the subject of probability theory is “indefinitely long sequences” — we might helpfully think of these as infinite sequences (though perhaps here is a subtle difference worth thinking about). Instead of starting with experiments, we start with an indefinitely long sequence, from which we deduce the frequencies. For example, suppose we start with the infinite sequence

Under certain mathematical conditions this sequence will have something called a limiting relative frequency (of ‘1’s to ‘0’s, for example). An intuition here is that an infinite sequence of flips of a fair coin where heads is a ‘1’ and tails is a ‘0’ would correspond to a sequence with a limiting relative frequency of ‘1’s of 1/2 (though this is just a helpful intuition).
The idea is that from these frequencies we can predict the outcomes of future indefinitely long runs. In order to do this we would have to have a theory — the theory of probability — and the correct frequency to input into the theory to give us predictions. This is why the long run frequencies are “effectively constants” — they are supposed to play the same role.
It is worth remarking here that this definition of probability as the limiting relatively frequency of certain events in an infinite sequence — sometimes called frequentism — has fallen out of fashion, both for philosophical and mathematical reasons. However, back in 1937 it was still a contender (Kolmogorov had only formalized his now canonical probability axioms in 1933).
Again, if we do not get the right prediction, this could be either due to some kind of experimental error such as the sequence not being long enough, or because our theory of probability is wrong.
This aim is mistaken. We must be satisfied with our theory if it is better than any other possible theory, i.e. if it satisfies some test (which we choose) such as, that its predictions shall be right more often than those of another theory or that the differences between the predictions and the results shall be irregularly distributed.
Instead of this more rigid axiomatic account of how we should use probability, Ditchburn advocates for a more pragmatic (perhaps?) use of probability. That is, if we want to do something like make accurate predictions about future events, then can we see if our theory of probability does a better job than other competing theories.
The comment about the differences between the predictions and the results being irregularly distributed is an interesting one. He doesn’t talk more about it, but I think the intuition here is something like the following. Whenever we make predictions about future events there will always be some degree of error. We can investigate the character of this error. If the error is not distributed randomly, that is, if there is some pattern to the error, then this suggests we are not doing the best we can with our predictions, since we have failed to account for this error. However, if the distribution of errors is patternless, then we have incorporated all of the information as best we can, and our theory is adequate relative to our epistemic limitations.
This also reminds me of one assumption needed for linear regression to work properly. This is the assumption that the errors of our model (also called residuals) are statistically independent from each other. If they are not, then we do not have a guarantee that our model is making optimal predictions. Again, there is some structure in the data which our models does not incorporate, and this it is not the best we could be doing.
The proof that those indefinitely long runs which escape Von Mises’ criterion are very rare is interesting, but only because a similar proposition must be true of finite runs which are very long. But we must recognise that even for indefinitely long sequences we cannot derive laws which are certain and immutable.
Von Mises was a champion of frequentism — this view that probability is defined as the limiting relative frequency of an infinite sequence. However, he has more stringent criteria on what kinds of infinite sequences could be the bearers of probability. For example, consider the infinite sequence

If this sequence were to go on forever with the same pattern, then the limiting relative frequency of ‘1’s would be 1/2. However, this sequence doesn’t fit our intuitions as one with a probability, because I can predict perfectly the next digit in the sequence, since it is composed of alternating ‘1’s and ‘0’s. Imagine if you had a coin that always alternated the outcome of a flip, so you had a sequence “heads, tails, heads, tails, heads…” — you wouldn’t say the coin was probabilistic at all.
Thus, Von Mises had additional criteria. In particular, one of the criteria was that the sequence had to be patternless. He called a sequence that satisfied all of his criteria a kollektiv. Probability was only defined for kollectives. Defining this with mathematical precision is a whole other post, but it suffices to say that notions of pattern are tricky, and depend on things like the kind of computational resources one is allowed to use to define a precise notion of pattern. However, a few different notions were proposed.
I’m not exactly sure which result Ditchburn is referencing here, and in particular I am not sure what precise notion of “very rare” he is using. (If anyone knows please leave a comment!) However, the important thing for Ditchburn seems to be that the only reason this is result about infinite sequences is interesting is because of the relationship it has to very long finite sequences — again, elements of pragmatism, or at least empiricism.
It is interesting to consider how the experimental scientist deals with Dr. Hempel’s point that it is necessary to define a probability relative to a given sequence. All probability theories, like other scientific theories have their basis on the idea of some relatively permanent and unchanging law which may be called ‘invariable — consequence’ or causality (in a nonmetaphysical sense).
We can see why, on the frequentist notion of probability, it would be necessary to define probably with respect to a certain sequence. Suppose, for example, you had an infinite sequence

For this sequence, we might say 1 has the probability 1/6. However, in a different sequence,

we might say it has probably 3/4. Thus, the probability of 1 is totally dependent on the sequence of which it is a part.
However, in order to use probability to do science, we want to be able to formulate and test different laws governing events. This is a little tricky if the probability of an event is dependent on the sequence of which it is a part. We will have a slightly longer discussion of this after the next quote.
I also find the “in a nonmetaphysical sense” amusing — the journal in which this remark was published, Erkenntnis, was notoriously anti-metaphysical at the time. The founders of the journal were both closely associated with the Vienna circle, and in its early days it served as an outlet for their particular scientific worldview.
In probability it is assumed that certain elementary events are equally probable and that they remain equally probable. For insertion into the axiomatic theory we use frequencies derived from past experiments and the enumeration of these experiments specifies the sequence as Dr. Hempel requires. The result of the calculation is to predict the results of certain experiments in the future and the instructions for carrying out these experiments specify the sequences again.
Let’s think about this. Consider, for example, rolling a die. If we want to calculate the probability of getting two 6s in a row, we take the probability of the elementary events, P(getting a 6) = 1/6 in this case case, and multiply them together to get the prediction.
How did we get 1/6? Well, we’ve seen a lot of die rolls in the past, and we have testimony from others, and very close to 1/6th of the rolls we and others have seen came up 6. So we think that the probability of geeting a 6 is 1/6.
However, this it totally subject to the sequence with respect to which we choose to define the probability of getting a 6. Consider, for instance, if we included in our sequence only rolls whose result was even. Then it would seem that the probability of getting a 6 is 1/3, not 1/6. Or suppose we only included odd roles — then it would be 0. Or suppose only rolls that came up 6 — then it would be 1!
Indeed, in a short paper of the same issue of Erkenntnis, Hempel argues that probability must be a three place relation involving as property, a number, and a sequence. Thus, in order to make any of this rigorous and helpful, we can’t only talk about the probability of 6, but we have to talk about the probability of 6 within a completely specified experimental protocol, which in turn will give us a precise way of generating the sequence, with respect to which we can define the probability of 6. This is what Ditchburn means by the enumeration of the experiments specifying the sequence.
Thus the sequence is always specified, though I must admit that the language of experimentalists is often careless so that the sequence is not clearly specified. Usually it is sufficient that if any method of selection has been at work in the original experiments the same selective factor shall be at work in the final set whose results are to be predicted. In other words the same physical “laws” are to hold good.
This is getting at the practical side of how we actually create these sequences. Instead of explicitly defining the enumeration procedure, scientists most of the time just assume that whatever method is producing the sequence will continue being the same. Usually it works, but this isn’t always true, especially if the experimental methodology is unclear. It seems that if scientists are to make this situation better, they should always clearly specify their enumeration procedure. And not just that, but when making predictions about future sequences of events, these should be enumerated so that they are part of the same overall sequence.
I suggest that ideally physics deals with its data in the following way. The results of past experiments are plotted in a configuration space. It is observed that they tend to cluster in certain regions. A law of geometry is then found such that when the configuration space is deformed according to this law the points are on the average distributed with equal density over the part of the configuration space to which the observations refer.
A configuration space is a way to represent different physical quantities in a space — they don’t have to be spatial features, they could be temperature or mass or luminosity, anything. So, for example, if we were doing experiments on the relationship between temperature, pressure, and volume, we could plot observations of different objects in a 3-dimensional configuration space.
We might see that they cluster in certain regions. For example, if we hold volume constant, we might find that our observations cluster in the high pressure high temperature and low pressure low temperature regions, but not in the high temperature low pressure regions.
We then look for a geometric transformation of the space that smooths everything out, making out observations equally dense. We can think of this transformation as encoding some kind of physical law — once we have incorporated all of the information from this law by deforming the space, everything now is equally dense — it looks ‘random’ to us.
I mean that if the density over reasonably large areas of the deformed space were measured it would be the same everywhere, but that if small areas are taken then there are random fluctuations.
This echoes the idea of kollectives. Remember a key part of the definition of a kollectiv is that it is patternless. However, it also has to have a relative limiting frequency. Thus, kollectives are supposed to exhibit a global uniformity — the limiting relative frequency — while at the same time having no local patterns. Locally, we should not be able to predict the next digit better than the limiting relative frequency.
Thinking of the configuration space now, there is a similar idea. We start off by transforming the space with a certain geometric law so that it is equally dense everywhere — this is a kind of global regularity condition, similar to a limiting relative frequency. However, locally, we have these random fluctuations — we can’t predict things perfectly.
The law of deformations of the configuration space is essentially the field equation of classical physics and it is the function of probability theory to take account of the local fluctuations. Prediction is made by assuming that the with the same geometrical law the distribution of points points is uniform over the parts of the configuration space for which no observations have been made and that the same random fluctuations occur in these parts of space. Thus the probability theory is inevitably allied with a field theory.
I’ve left some typos in on this one, since I don’t quite know how to clear some of them up. Despite this, I think we can extract the main ideas.
We use the laws we have found — in this particular example he has in mind, the field equation of classical physics — to turn the configuration space into something with a uniform density. As we noted early, we are basically changing the configuration space into something resembling a Von Mises kollectiv so that we can treat it with the mathematical theory of probability.
Although we have only ever made a finite set of observations, we assume that we can extend the field equation/law we have found to the whole space, making the whole space subject to the frequentist-style probability calculus.
In order for probability to apply in the context of this frequentist framework we need a kollectiv, or something similar. It is in this sense that “probability theory is inevitably allied with a field theory” — we use the field theory to made configuration space something to which probability can be properly applied.
That is the end of the note. As I mentioned earlier, this frequentist approach to probably is largely dead within philosophy — most of us are now Bayesians. I think this is definitely the right move. However, it is interesting to see the kind of challenges and considerations frequentists were making as they developed the theory. I also find it really interesting to see the way in which physics was essential for driving probability theory forward — especially in this last paragraph, we see a kind of beautiful way of turning observations in a configuration space into something to which frequentist notions can be applied.
Even if at the end of the day I am not a frequentist, understanding the logical structure of frequentism is helpful for gaining clarity on my own thoughts about the philosophical foundations of probability.
