Decision theory seeks to understand how rational agents should act. More specifically, I am talking about normative decision theory. There is also descriptive decision theory which tries to characterize how people in fact act. For this post (and most of my posts) I will focus on normative decision theory.
Importantly, the “should” here is not an ethical or moral imperative. Rather, decision theory tries to characterize how a rational agent should act given her beliefs and desires, whatever they may be. Decision theorists are not in the business of telling an agent what she should value.
One of the central results of decision theory is the claim that an agent should act to maximize expected utility. We’ve seen in the past that we can characterize a rational agent’s degrees of beliefs as probabilities. The idea can then be stated informally as follows: when choosing an action, the agent should choose the action with the maximum expected value.
One of the main justifications of expected utility theory involves something called a representation theorem. In general, a representation theorem is a result that shows that a certain relation among objects can be represented by a mathematical object. My previous post talked about this is the context of measurement. In the context of decision theory, we start off with an agent’s preferences among gambles. For example, an agent might prefer a gamble in which she gets $10 if a coin comes up heads and $0 if it comes up tails to one in which she gets $5 if it comes up heads and $3 if it comes up tails. If the agent’s preferences satisfy certain rationality constraints, then we can prove a representation theorem that says we can represent the agent as if she were maximizing some utility function (capturing what she values) with respect to some probability function (capturing her beliefs). Thus, any agent whose preferences over gambles (we can also think of these as actions) is rational can be thought of as an expected utility maximizer.
However, to some this can be seen as working backwards. Consider the introduction to our paper this week:
Naive applications of decision theory often assume that it works by taking a specification of probabilities and utilities and using them to calculate the expected utilities of various acts, with a rational agent being required to take whichever act has the highest (or sufficiently high) expected utility. However, justifications of the formal framework of expected utility theory generally work in the opposite way — they start with an agent’s preferences among acts, and use them to calculate an implied probability and utility function. The theory of expected utility is justified by showing that any agent who satisfies some reasonable seeming constraints on her preferences can be represented in such a way, by postulating appropriate abstract “probability” and “utility” functions.
Easwaran, p. 1
The tension is that we often want to think of decision theory as taking an agent’s beliefs and utilities as given, and then generating a rational (set of) action(s). However, as Easwaran points out, representation theorems go the other way.
There is a lot of disagreement about whether or not this is a problem. I don’t plan to take a stance on that issue in this post, but I do think it helps to understand the goal of Easwaran’s project. Instead, I want to focus on two key innovations that Easwaran makes while developing his alternative approach that I think are very interesting. The first is the extension of his framework to include multiple state spaces, and the second is the way he integrates probability into his account (I think this later innovation is particularly beautiful). If neither of those things meant anything to you, by the end of this post I hope they will.
***The original paper can be found here.***
Let’s get the standard framework of decision theory on the table so that we can understand the ways in which Easwaran’s account differs. I’ve already given a bit of a introduction to the standard Savage framework here, but I’ll quickly run through it again. I focus on Savage’s framework because this is the framework to which Easwaran’s account is the closest.
In the Savage framework we have a set of states, 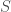
We also have a set of outcomes, 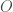
Finally, we have a set of acts, 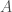
bring umbrella (raining) = dry
bring umbrella (not raining) = dry
leave umbrella (raining) = wet
leave umbrella (not raining) = dry
Then, if we were to continue on the project of decision theory in the Savage framework, we would show that if an agent’s preferences over actions satisfies some plausible rationality axioms, then the agent can be represented as an expected utility maximizer. Again, this approach starts with preferences over acts and then derives appropriate probability and utility functions for the agent.
Easwaran builds things up a little differently. Though his framework still has states, he allows for arbitrarily many state spaces. He writes
Unlike standard decision theorists, I do not assume that there is a single set
Easwaran, p. 10
So instead of just a single state space 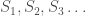
For instance, if one act involves flipping a coin, and another one doesn’t, then the former act is going to have states in which the coin comes up heads and other states in which the coin comes up tails.
Easwaran, p. 10
So, for example, I might be considering the act Easwaran describes in which I flip a coin, and another act in which I roll a die. It makes sense that these acts should have different state spaces, since they depend on different things, some of which may or may not happen depending on which act I choose.
I think this is very nice conceptually. It gives a very clean way of thinking about what features of the world upon which different acts depend, and as Easwaran points out it avoids the need for some strong metaphysical commitments:
Perhaps the agent thinks that there are some objective features of the world that causally determine how the coin would have come up, even if the coin isn’t actually flipped, but this seems like a strong metaphysical commitment.
Easwaran, p. 10
Beyond this advantage there are a few others as well. I won’t get into too much detail, but it allows for a flexible way of thinking about act-state dependence, which was one of Savage’s concerns about his own framework. For readers familiar with it, this can provide us with a different way to think about the Newcomb Problem (see footnote 4 on page 10).
So this is one of the two innovations I found particularly interesting. (Even though Easwaran cites a proposal of Frederick Schick’s that we move to framework with multiple state spaces, Easwaran put in the work to follow through on this proposal). In order to understand the other — how he incorporates probability into the framework — we need a bit of a better understanding about how we can compare acts defined on different state spaces.
Instead of a preference ordering on acts like in the Savage framework, the Easwaran framework starts with an agent having preferences over outcomes. He keeps it pretty flexible and open what kind of conditions the agent’s preferences must satisfy, so I won’t get into too much detail. He then shows how you can use these preferences among outcomes to induce a (partial) preference ordering among acts defined on the same state space.
Again, this is a little abstract, so let us consider an example. Suppose I am considering the two acts from before,
bring umbrella (raining) = dry
bring umbrella (not raining) = dry
leave umbrella (raining) = wet
leave umbrella (not raining) = dry
on the state space 
It is clear that this kind of comparison doesn’t always work since sometimes you may have two acts, neither of which clearly dominates the other. For example, how would you compare the act
strange-act (raining) = dry
strange-act (not raining) = wet
with the “leave umbrella” act from before? Neither completely dominates the other. Despite this initial weakness, Easwaran later defines ways to extend these kind of comparisons which, when supplemented with other assumptions, can recover expected utility maximization (though I am a little ahead of myself, since doing so requires incorporating probability — however if you are curious, see theorem 14 in the paper).
However, this only allows us to compare acts defined on the same state. What about acts defined on different states?
Easwaran introduces correspondences as a mathematical formalism for connecting different state spaces (he again cites Schick as inspiration, but notes that he generalizes Schick’s idea). He writes
The basic idea is that even though two acts may be defined on different state spaces, there may be an important sense in which states in once space naturally “correspond” to states in another space. If act A involves flipping a fair coin, and act B involves rolling a six-sided die and seeing whether the face that comes up is odd or even, then there is a sense in which one can say that heads corresponds to odd and tails to even, or vice versa.
Easwaran, p. 12
So the purpose of these correspondences is to allow us to compare actions defined on different state spaces. However, we can also have a correspondence from a state space to itself. For example, if we have the state space 


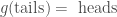
Again, we could also apply such an idea to compare acts defined on different state spaces — like the example he gave in the quote about flipping a coin and rolling a six-sided die. In fact, Easwaran goes on to define the notion of a groupoid which, informally, gives all the correspondences between state spaces, and thus induces a kind of comparability on the different state spaces (and thus the different acts).
Now, the astute reader might have noticed that making the earlier correspondence
This is precisely correct. And indeed, this leads us to the second innovation. The idea here is that we use the agent’s probabilities (either numerical or qualitative) to generate the set of correspondences. So, while it is the agent’s preferences over outcomes that give us the preferences over actions given a certain set of correspondences (the groupoid), it is the agent’s probabilities (beliefs) that give us the correspondences themselves. In other words, the probabilities give us the sets of states that are interchangeable (like the even and odds of a die and the sides of a coin).
I think that this is a particularly beautiful way to incorporate probability into a framework of decision making. It makes the role of probability clear: to pick out the states that are (in some sense) equivalent for decision making, and those which aren’t.
To conclude, I will recap, and show how this addresses Easwaran’s main concern.
Instead of starting with preferences over acts, we instead start off with preferences over outcomes (utilities), and probabilities. We use the probabilities to make comparisons between actions defined on (different) state spaces possible, and then we use the utilities to actually make the comparisons between acts. Given certain conditions on the utilities and probabilities, we have the result that resulting preference ordering over actions will agree with the expected utility ordering; this ends up looking exactly like the naive recommendations of classical decision theory.
There is a lot going on in this paper, and Easwaran does a great job of carefully walking the reader through his framework and showing exactly what you need to get different results off the ground. I highly recommend working through this paper for anyone interested in decision theory.
