The standard Bayesian story goes something like this: probabilities represent a rational agent’s degrees of belief. When the agent learns something new she conditions on it, meaning that she updates her probabilities according to Bayes’ rule.
Importantly, the interpretation of the probability function is that it represents the agent’s degrees of belief about how likely a proposition is to be true. If an agent’s degree of belief in a statement is 0.75, this means her credence that the statement is true is 0.75. As Olav Benjamin Vassend points out in a recent paper, this can actually conflict with our statistical practice.
***The original paper can be found here.***
Vassend identifies what he calls the interpretive problem. Somewhat dual to Bayesian epistemology is Bayesian statistics. In Bayesian statistics we have a set of candidate hypotheses, and a prior probability distribution over them. For example, consider you are learning about the bias of a coin. Your hypothesis could be every real number between 0 and 1, and you could have a flat prior on it, or one sharply peaked at 0.5 (capturing your background knowledge that most coins are fair).
In general, we have a set of possible hypotheses indexed by a parameter 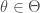

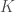


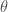
Importantly, in order to use all of this information to then learn, we need to have prior probabilities—these would take the form 
However, Vassend claims that, when we look at actual statistical practice, this cannot be true. When statisticians and scientists use Bayesian statistics they are often confident that all of the statistical models they write down are in fact false. They choose their class of models often because they think they are tractable and have a decent chance at being good enough predictors of the actual data. Thus, Vassend points out, the standard Bayesian account of what the probability assigned to these statistical models are cannot be right. This is the interpretive problem—how are we to interpret the probabilities in Bayesian statistical models?
Indicating a first attempt to solve this problem Vassend writes
One response to the interpretive problem that initially strikes many philosophers as attractive is to try to change the algebra over which the probability function
p. 701ranges. For example, some might be tempted to consider the algebra generated by the associated propositions
, for each
, or something similar. The idea is that even if
Indeed, when I first read Vassend’s account of the interpretative problem I thought that changing the algebra might be the solution. (Here algebra just means something like the set of propositions over which a probability function is defined.) However Vassend points out some major difficulties for this account.
One is that scientists do no actually consider hypotheses of the form
The main issue is that while the actual statistical models do give probability distributions over hypotheses (think of the case of the bias of a coin), propositions of the form 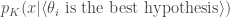
A final issue for this approach is that “important evidential relationships between the hypothesis and evidence will generally be lost” (p. 702). One example that Vassend gives is of conditional independence. The technical details need not concern us here. Vassend’s example of coin tosses gives an intuition:
Each possible bias of the coin renders all future coin tosses conditionally independent. The coin bias model is therefore an adequate statistical model for coin tossing in the sense that it captures the conditional independence relations between evidence and hypotheses that de Finnetti’s theorem says it is possible to capture. However, note that there is no reason to think that a proposition like
p. 702will likewise render the coin tosses conditionally independent.
So, to summarize, the standard Bayesian interpretation of the probabilities in a statistical model representing degrees of belief that a propositions is true fails because the practitioners actually think all the models are false (and do not move to a different algebra). Furthermore, moving to a different algebra in order to keep the standard interpretation does not preserve the conditional probabilities and providential relationships it would need to in order to be an adequate solution. Thus the interpretative problem remains.
Vassend then considers two different approaches to solving this problem. He then argues that these two approaches are in some sense equivalent to each other. Finally he argues that these solutions lead to pragmatics infecting Bayesian inference.
Both of the approaches he considers have the important feature that instead of changing the algebra, they instead try to change the interpretation of the probability function itself. This is the important difference that avoids all of the problems we noted above.
First Vassend proposes verisimilitude probabilities. The core of this interpretation is that
Instead of interpreting
pp. 703-704.
If we consistently adopt this interpretation of probability (within the context of these statistical models) then this avoids the interpretive problem. Furthermore, it also avoids all of the problems with changing out algebra, because here
In other words, according to the verisimilitude interpretation, a probability assignment to
p. 704
Vassend notes that the verisimilitude interpretation depends on a particular verisimilitude measure, and that we might choose this measure based on our purposes. So here we see the beginning of the pragmatics encroaching on our epistemology.
Vassend summarizes the second approach, the counterfactual approach, in the following:
[S]uppose
p. 710
Again, like in the verisimilitude case, we need some kind of similarity measure 
Both the verisimilitude account and the counterfactual account rely on different measures—
Furthermore, to the extent that our choices of
For me it is an open question about how much either of these accounts connect up to epistemology, and, if they do deviate, how far.
