“Learnability can be undecideable” argues that the current mathematical frameworks we use to understand learnability are deeply flawed. It has been making big waves in the machine learning community, due to its rather spicy thesis. Thus, I figured it would be a good paper for me to review, and to explain its argument and implications.
***The original paper can be found here.***
The field of machine learning looks both at how we might build machines to learn certain concepts and which concepts are in principle learnable. For example, I might be interested in having a computer that can tell whether or not an email I receive is spam. In order to design such a program I must not only think about the program, but also how difficult it is to learn to distinguish “spam” from “not-spam”.
This paper is more focused on the way in which we characterize how difficult it is to learn a given class of concepts. It is not that we are trying to characterize how difficult it is to learn a particular concept, but rather how difficult it is to learn a class of concepts. For example, this approach would not be interested in how challenging it is to learn French, but rather how challenging it is to learn a language in general.
Knowing which types of concepts are learnable and which aren’t is very useful; it helps us to decide which kind of problems we would want to tackle with machine learning. If we know in advance that a class of concepts is unlearnable, then we wouldn’t want to waste time by having a machine learner try to learn a concept from that class.
Ben-David et al. then note that we have rich mathematical frameworks for characterizing learnability. One of the main frameworks is probably approximately correct (PAC) learning. In particular, not only is this a useful framework, but with it we can characterize the learnability of a concept class by a single parameter: Vapnik-Chervonenkis (VC) dimension. Each concept class will have a VC dimension, and it is a theorem that a class is learnable if and only if its VC dimension is finite. The smaller it is, the less data the learner needs to successfully learn a concept from that class.
Thus, VC dimension is a fairly general way to characterize the (PAC) learnability of a class. There are generalizations of PAC and VC dimension, and all use similar definitions. However, as a corollary to the main result (the title) of their paper, Ben-David et al. claim that there can be no general dimension (like VC dimension) that characterizes learning.
What does it mean for learnability to be undecideable? As they put it, there are “simple scenarios where learnability cannot be proved or refuted using the standard axioms of mathematics” (44). In other words, the standard axioms of mathematics are mute on whether or not some simply characterized concept class can be learned. This is pretty surprising. We have this whole mathematical framework set up in order to answer exactly this kind of question, and yet Ben-David et al. show that not only have we not yet figured out how to characterize whether or not an arbitrary concept class is learnable within this framework, but that this is fundamentally impossible.
How do they do this? The broad strokes of the strategy are as follows: first, for a particular simple machine learning problem, they show that learnability is equivalent to compression (of a set into a smaller set) in some sense. Then they show that compression is intimately linked to the cardinality, or size, of a set. Then they show that the size of the set in the machine learning problem depends on the continuum hypothesis (which I will discuss later), which is famously independent of the standard axioms. Thus, the argument goes from learnability, to compression, to cardinality, to the continuum hypothesis. Since the standard axioms of mathematics are insufficient to determine whether or not the continuum hypothesis is true, they are also insufficient to determine whether or not the simple concept class Ben-David et al. construct is learnable.
I won’t go into the details of the proofs; those are already in the paper for those want to understand the details. But I will provide a sketch of some of the steps, in order to convey the spirit of the argument.
In order to show the link between learnability and compression they consider what they call the finite superset reconstruction game. Consider that we have some set of points 

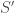
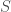

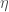

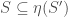
Obviously, if Alice just sends 
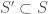
Clearly, if
How does this connect to learning? The authors suggest that we think of Alice and Bob as two different parts of a learning algorithm. In particular, we might think of Alice are the part of the algorithm that receives data (
This makes the link between compression and learning a little more obvious. Since EMX can be in some sense be described as this game, we can characterize the learnability of the concept classes in EMX according to how much Alice can compress
Now we turn to the connection between compressibility and cardinality. So far it has seemed that
Suppose that we have some infinite set 

Now, the question is, since
The answer depends on the cardinality of 
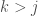


We know from Cantor’s diagonal argument that the cardinality of the real numbers is larger than the carnality of the natural numbers. However, there is a question–is the cardinality of the real numbers equal to 
The hypothesis that the answer to this question is “no,” and that the cardinality of the reals is 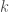
For the EMX problem used throughout the paper, the set ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=404040&s=0&c=20201002)
The set
Thus, we see that whether or not CH is true directly influences whether or not a particular problem is learnable. Facts about whether or not a certain concept class is learnable are independent of the standard axioms of mathematics. As a corollary, Ben-David et al. show that because of this independence, there can be no parameter characterizing learnability, like we intended with VC dimension.
This is an unhappy state of affairs. The foundations of machine learning try to answers questions about what kind of concept classes are learnable. To do this, we have developed a rich, expressive mathematical framework. However, Ben-David et al. show that this framework leads to learnability being undecideable.
There are a few lessons we can learn from this. As the authors write, “when trying to understand learnability, it is important to pay close attention to the mathematical formalism we choose to use” (48). They point to a particular problem in the formalism: our choice to talk about functions rather than algorithms. In our discussion of the finite superset reconstruction game and learning in general, we have focused on whether or not certain compression functions existed. There is a great advantage to this. The math is easier to work with, and as the authors point out, the current frameworks “separate the statistical or information-theoretic issues from any computational considerations” (48). However, there are many functions that are not computable–this means that no computer, no matter how much time or memory it was given, could compute the function. Thus, the set of functions on these kind of infinite sets is a lot larger and more abstract than the set of computable functions. Furthermore, if we get even more specific than computable functions and want to talk about algorithms, we are bringing even more computational details to the table.
When I first heard of the result of this paper an odd question occurred to me, the answer to which I suspected was “no”: did this imply that we could use the physical fact of whether or not an actual computer could learn something to determine whether or not CH were true? However, we see from this insight of functions versus algorithms that the answer is in fact “no.” The learning frameworks we have in place now talk about the existence or non-existence of functions, not algorithms. However, any machine I build would be constrained by the physical laws, and by the limits of computation. Thus, whether or not there exist physically implementable algorithms that can learn is a different question from whether or not there exist functions that can learn, and so we could not infer from the learning success or failure of a physical machine that CH is true or false.
We have a methodological moral for computer science. When choosing a formalism in which to construct our best characterizations of learnability, there are trade-offs between ease and expressibility on the one hand and decideability on the other. In particular, avoiding the weeds of the computational details may push the whole enterprise to the point where it is too divorced from our purposes for it to be useful for us.
